crawling - basic
3 minute read
여기서 사용한 라이브러리
beautifulsoup4, lxml, pandas
웹 데이터를 읽어오는 모듈 : Beautiful Soup
Naver 코스피 정보 가져오기
>>> from urllib.request import urlopen
>>> from bs4 import BeautifulSoup
>>> quote_page = 'http://finance.naver.com/sise/sise_index.nhn?code=KOSPI'
>>> page = urlopen(quote_page)
>>> soup = BeautifulSoup(page, 'lxml')
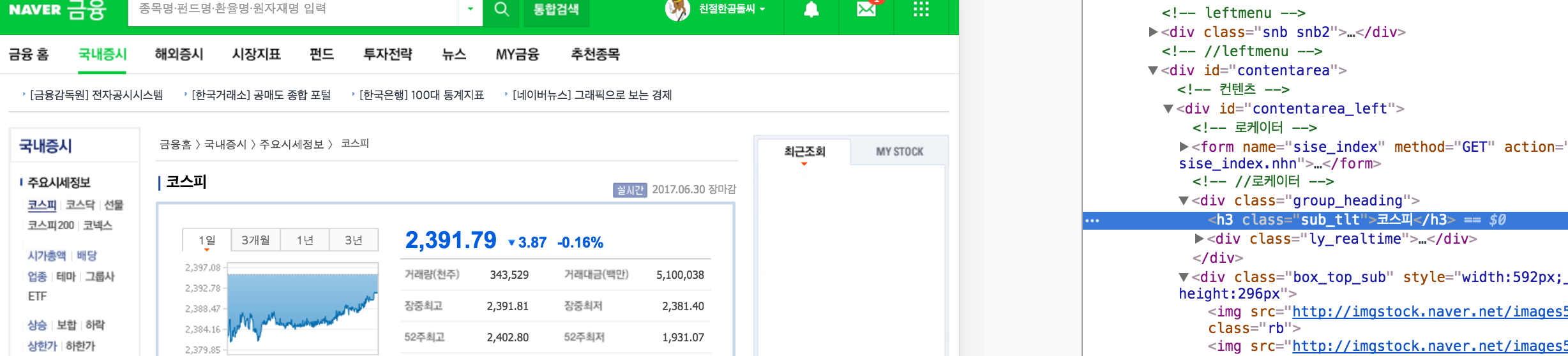
>>> name_box = soup.find('h3', attrs={'class':'sub_tlt'})
>>> name = name_box.text.strip()
>>> name
'코스피'
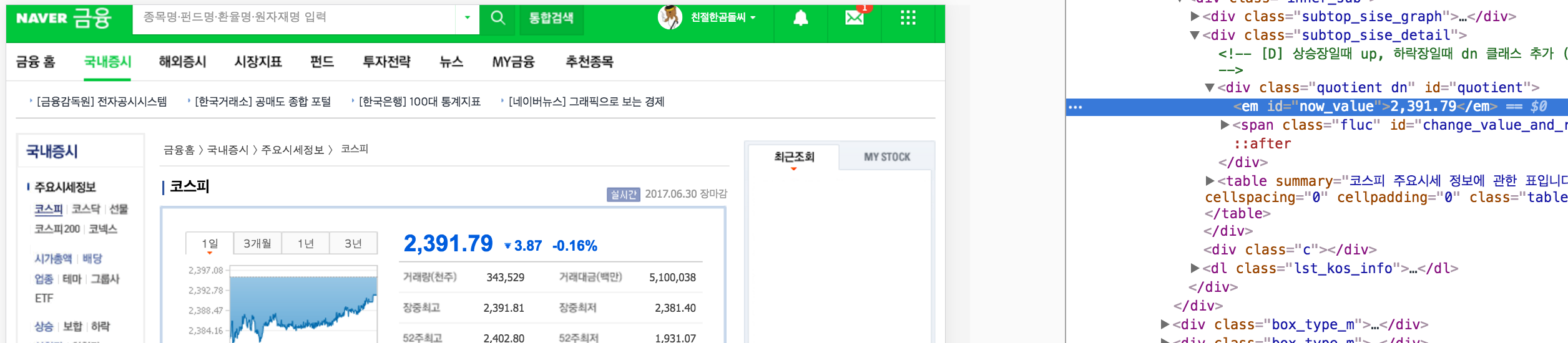
>>> price_box = soup.find('em', attrs={'id':'now_value'})
>>> price = price_box.text
>>> price
'2,391.79'
Naver 웹툰 리스트 가져오기
>>> from urllib.request import urlopen
>>> from bs4 import BeautifulSoup
>>> url = 'http://comic.naver.com/webtoon/weekday.nhn'
>>> html = urlopen(url)
>>> soup = BeautifulSoup(html, 'lxml')
>>> toon_title = soup.find_all('a','title')
>>> for i in toon_title:
... print(i.text)
...
신의 탑
뷰티풀 군바리
윈드브레이커
대학일기
귀전구담
소녀의 세계
평범한 8반
마왕이 되는 중2야
선천적 얼간이들 (재)
...
CGV 영화 순위 뽑기
>>> from urllib.request import urlopen
>>> from bs4 import BeautifulSoup
>>> import pandas as pd
>>>
>>> url = 'http://www.cgv.co.kr/movies/?ft=0'
>>> html = urlopen(url)
>>> soup = BeautifulSoup(html, 'lxml')
>>>
>>> rank = soup.find_all('strong','rank')
>>> title = soup.find_all('strong','title')
>>> open_ticket = soup.find_all('span','txt-info')
>>> rank_list = []
>>> title_list = []
>>> open_list = []
>>>
>>> for i in range(len(rank)):
... rank_list.append(rank[i].text)
... title_list.append(title[i].text)
... open_list.append(open_ticket[i].text.strip()[:10])
...
>>>
>>> data = {'Rank':rank_list, 'Title':title_list, 'Ticket open':open_list}
>>> df = pd.DataFrame(data)
>>> df.head(7)
Rank Ticket open Title
0 No.1 2017.07.05 스파이더맨: 홈커밍
1 No.2 2017.06.28 박열
2 No.3 2017.06.21 트랜스포머: 최후의 기사
3 No.4 2017.06.28 리얼
4 No.5 2017.06.28 지랄발광 17세
5 No.6 2017.06.22 언더더씨
6 No.7 2017.06.28 헤드윅
>>>
I feedback.
Let me know what you think of this article in the comment section below!
Let me know what you think of this article in the comment section below!
comments powered by Disqus