우편번호 자동 크롤링하여 엑셀에 입력하기
추석을 맞이하여 고객들에게 우편을 보내는 업무가 들어왔습니다.
옆에 직원이 고객정보 리스트를 보며 한숨을 내쉽니다.
1000건 가까이 되는 고객들의 주소에는 우편번호가 입력되어 있지 않았습니다.
우편을 접수하려면 각각 주소에 우편번호를 하나하나 입력을 해주어야 하기 때문입니다.
추석까지는 얼마의 시간이 남지 않았고, 손으로 일일이 초록색 창에 주소를 입력하여 우편번호를 입력하기에는 시간도 오래 걸릴뿐더러, 굉장히 비 생산적인 노동이었습니다.
그래서 옆에서 지켜보다가, 그냥 for문을 돌려버리면… 이라는 생각에 간단한 프로그램을 만들어서 그 문제를 해결하기로 했습니다.
(해당 포스트는 모든 문제를 해결한 후 작성한거라 실패한 부분에 대한 캡쳐화면이 없습니다..)
우선 우편번호와 관련된 API를 검색해보니 우체국에 openAPI가 있다는걸 알게되었습니다.
secret key를 발급받고 짜잔!!!
…
원하는 결과가 출력이 되지 않습니다.. 문서도 꼼꼼히 읽었는데.. 결과가 안나옵니다.
무엇이 문제일까.. 무엇보다 시간이 없는 관계로 API는 건너뛰고 초록창에 주소를 검색하는 크롤러를 만들어서 해결하기로 했습니다. (API보다는 속도가 느릴꺼라 생각했지만, 크롤러로 해결하는 것이 현재 상황에는 더 빠르다고 판단하였습니다.)
우선 가상환경을 하나 만들어 줍니다.
$ pyenv virtualenv 3.5.2 zip_code
$ pyenv local zip_code
저는 python 3.5.2 버전을 주로 사용해서 3.5.2로 셋팅하고 가상환경명은 zip_code라고 정의했습니다.
그리고 지금부터 작업할 환경을 방금 만든 가상환경으로 적용시켰습니다.
그럼 이제 필요한 패키지를 설치합니다. 우선 크롤링을 할꺼니 BeautifulSoup, 엑셀 파일을 읽고 쓰고 저장할꺼니 openpyxl. 이렇게 두가지 패키지를 설치합니다.
$ pip install bs4
$ pip install openpyxl
우선 엑셀에 있는 주소를 초록창에 검색하게 만들기 위해 주소를 추출합니다.
import openpyxl
wd = openpyxl.load_workbook('zip.xlsx')
ws = wd.active
def zipcode():
for r in ws.rows:
row_index = r[0].row
name = r[1].value
phone = r[2].value
address = r[3].value
zip_c = bs(address)
현재 읽어들일 파일은 인덱스, 고객명, 연락처, 주소 순으로 컬럼이 이루어져 있습니다. 즉, 주소 컬럼을 읽어서 변수로 넘겨야 합니다.
위 코드로 엑셀파일을 읽어들여 각각 변수에 넣습니다.(새로 엑셀파일에 내용을 복사하고, 우편번호를 추가하는 작업이기 때문입니다.)
주소를 address 라는 변수에 저장하고 우편번호를 크롤링할 bs라는 함수를 만듭니다.(bs…아름다운 수프의 약자네요.. 그냥 시간이 없어서 대충 만들다 보니 이름들이 참…)
크롤링하기에 앞서 초록창에서 우편번호가 어떤 태그로 나오는지를 파악해야 합니다.
샘플 주소는 한국의 아무 사이트나 들어가서 footer의 주소로 테스트하면 됩니다.
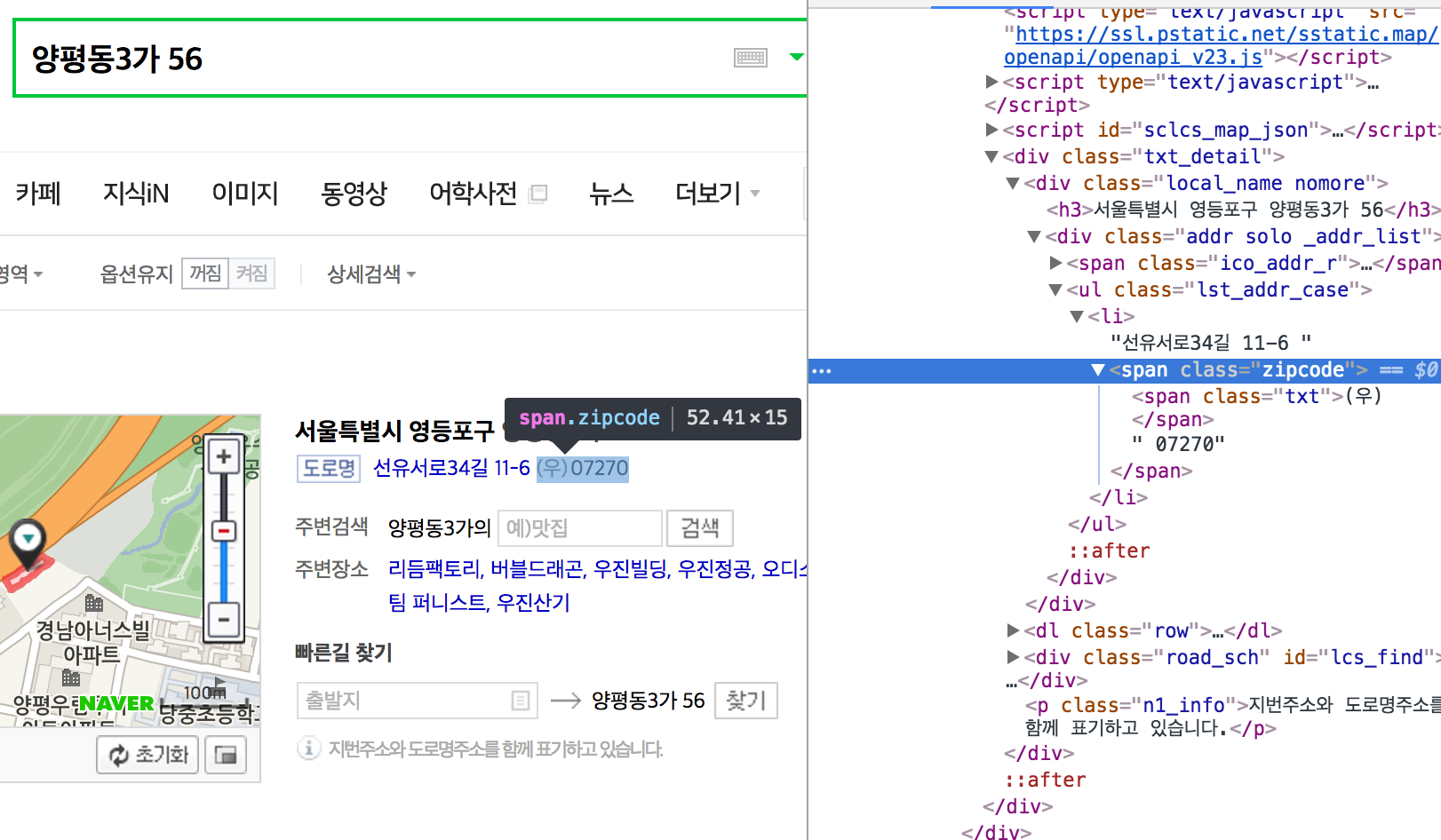
살펴보면 span 태그에 zipcode 라는 클래스안에 우편번호가 있는 것이 확인 되었습니다. 그러면 저 부분만 크롤링하면 되겠네요.
from urllib.request import urlopen
from bs4 import BeautifulSoup
def bs(address):
url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query="
html = urlopen(url + address)
bsObj = BeautifulSoup(html, "html.parser")
span = bsObj.find("span", "zipcode")
return span.text
실행해보시면 알겠지만 ascii 코드 에러가 일어납니다. address는 한글이고 url용으로 코딩을 해주어야합니다. (%ad%df 이런식으로 바꾸야 한다는 겁니다.) UTF-8, Ascii 등등 다 검색하다가… 그냥 파이썬 기본 패키지에서 다 해결이 된다는 것을 깨달았습니다. (삽질은 나중에 언젠가는 도움이 될만한 지식들을 채워주니까요 뭐…그렇습니다.)
urllib.parse 하나면 다 됩니다.
그럼 다시 코드를 짭니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib import parse
def bs(address):
url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query="
q = parse.quote(address)
html = urlopen(url + q)
bsObj = BeautifulSoup(html, "html.parser")
span = bsObj.find("span", "zipcode")
return span.text
잘 되는군요 ㅎㅎ 그럼 처음 계획대로 for문을 돌려보겠습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib import parse
import openpyxl
wd = openpyxl.load_workbook('zip.xlsx')
ws = wd.active
def bs(address):
url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query="
q = parse.quote(address)
html = urlopen(url + q)
bsObj = BeautifulSoup(html, "html.parser")
span = bsObj.find("span", "zipcode")
return span.text
def zipcode():
for r in ws.rows:
row_index = r[0].row
name = r[1].value
phone = r[2].value
address = r[3].value
zip_c = bs(address)
ws.cell(row=row_index, column=1).value = row_index
ws.cell(row=row_index, column=2).value = name
ws.cell(row=row_index, column=3).value = phone
ws.cell(row=row_index, column=4).value = address
ws.cell(row=row_index, column=5).value = zip_c
wd.save("zip_comp.xlsx")
wd.close()
zipcode()
… 에러가 발생합니다. text 속성이 없다고 하네요.
(이미 프로그램을 모두 완성하고 포스팅을 작성하여서 오류 화면은 캡쳐되지 않았습니다.)
여기서 두 번째 함정에 빠졌습니다. BeautifulSoup 객체인데 text 속성이 없다는게 말이 안됩니다. 엑셀 파일을 열어보니 테스트한 주소의 우편번호는 잘 들어갔습니다. (고객정보라서 캡쳐는 하지 않았습니다.) 그런데 두번째 주소는 입력이 않았습니다. 그래서 두번째 주소를 그대로 초록창에 넣어서 태그를 살펴봤습니다. (수동 디버그네요..)
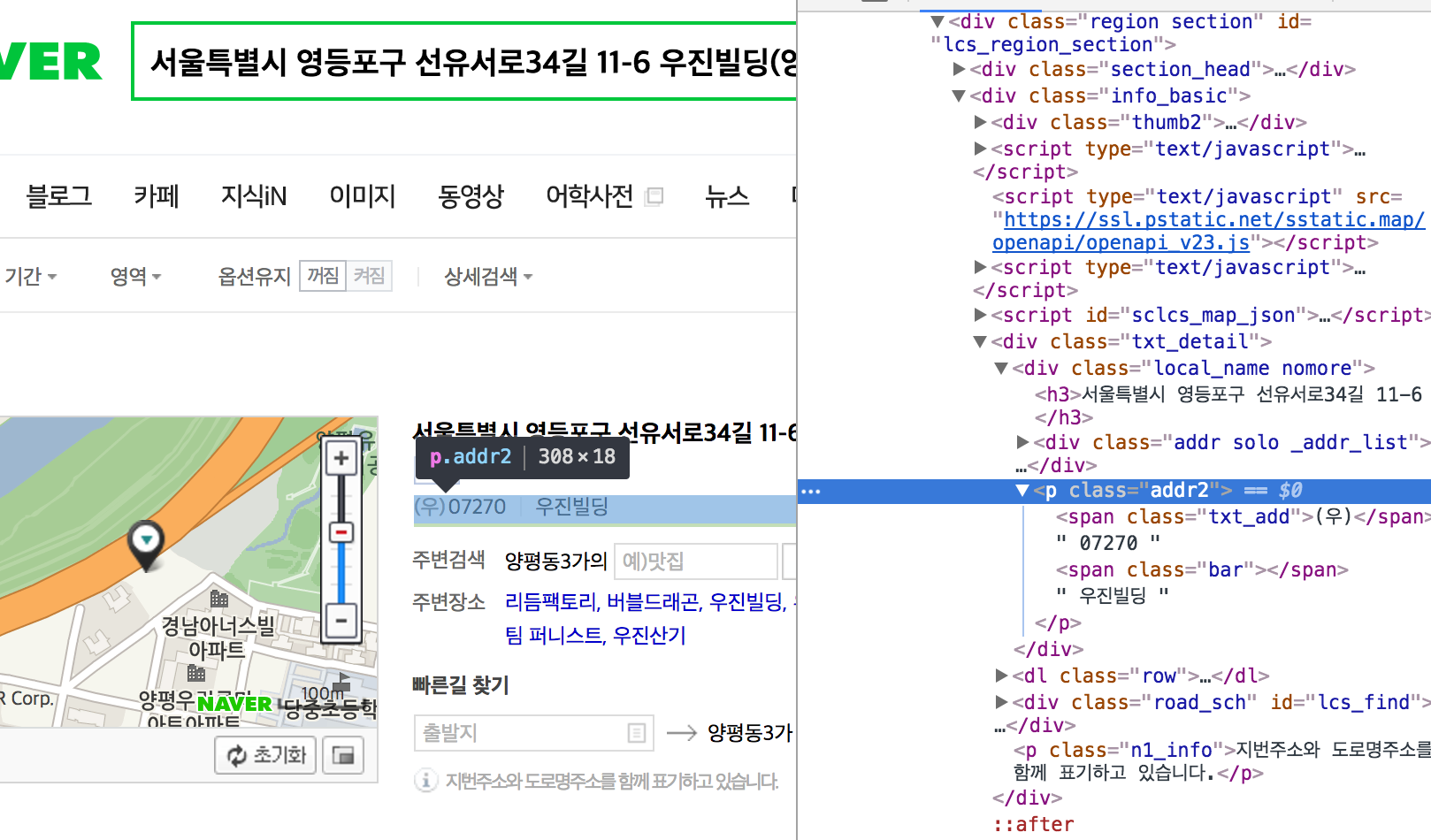
네… 태그가 다르네요.. zipcode는 어디로 가고 addr2이라는 놈이 튀어나왔네요. (지금 보니 zipcode는 지번이고 addr2는 도로명주소네요.)
당연히 zipcode 태그를 못찾았으니 text 속성도 없었던 겁니다. 그러면 해당 부분을 if문을 이용하여 추가해줍니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib import parse
def bs(address):
url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query="
q = parse.quote(address)
html = urlopen(url + q)
bsObj = BeautifulSoup(html, "html.parser")
span = bsObj.find("span", "zipcode") # 기존(지번)
span2 = bsObj.find("p", "addr2") # 추가(도로명주소)
if bool(span):
return span.text
elif bool(span2):
return span2.text
else:
info = "정보가 없습니다"
return info
엑셀 안의 주소는 지번과 도로명 주소가 마구 뒤섞여 있습니다. 그래서 구주소 태그(zipcode)를 먼저 검색하고, 없다면 신주소 태그(addr2)를 검색하여 우편번호를 뽑습니다.
요즘음 xx마을아파트.. 이런식의 주소들이 많이 있는데, 이런 주소는 초록창에서 단순한 프로세스로는 검색이 되지 않습니다. 고객들이 주소를 알려줄때 아파트 이름도 앞뒤를 바꿔서 알려주기도 하고… 아무튼 별의 별 경우가 다 있기 때문에 엑셀에 있는 주소의 일부는 초록창에서 검색이 바로 되지 않습니다. 그런건 일단 패스.
다시 코드를 정리하면
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib import parse
import openpyxl
wd = openpyxl.load_workbook('zip.xlsx')
ws = wd.active
def bs(address):
url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query="
q = parse.quote(address)
html = urlopen(url + q)
bsObj = BeautifulSoup(html, "html.parser")
span = bsObj.find("span", "zipcode")
span2 = bsObj.find("p", "addr2")
if bool(span):
return span.text
elif bool(span2):
return span2.text
else:
info = "정보가 없습니다"
return info
def zipcode():
for r in ws.rows:
row_index = r[0].row
name = r[1].value
phone = r[2].value
address = r[3].value
zip_c = bs(address)
ws.cell(row=row_index, column=1).value = row_index
ws.cell(row=row_index, column=2).value = name
ws.cell(row=row_index, column=3).value = phone
ws.cell(row=row_index, column=4).value = address
ws.cell(row=row_index, column=5).value = zip_c
wd.save("zip_comp.xlsx")
wd.close()
zipcode()
zipcode 함수에서 엑셀의 각 컬럼 정보를 읽어서 새로운 파일에 저장하고, 주소부분만 bs함수에 넘겨서 bs함수는 초록창을 크롤링하여 우편번호를 추출해서 zipcode에 반환합니다. 반환한 우편번호를 마저 엑셀에 저장하고, 이 작업을 반복하여 엑셀의 모든 고객의 우편번호를 입력하는 프로세스입니다.
이 작업으로 인해 1,000개 정도의 주소에서 970개 가량은 자동으로 채웠습니다. (앞에 언급했듯이 초록창으로는 찾을 수 없는 주소들도 꽤 많습니다..)
이 작업으로 무사히 일정을 마무리했고, 옆의 직원의 고민거리도 해결해 주었습니다. 위 코드는 Doky’s Git에 업로드 되어있습니다.
Let me know what you think of this article in the comment section below!